








最新大模型被质疑训练“刷分”,Meta承认有漏洞但否认作弊
- 情感
- 2025-04-08 15:17:04
- 9

科技巨头Meta回应了对公司最新开源AI(人工智能)模型Llama 4的质疑,否认该模型在训练集中作弊“刷分”。
当地时间4月7日,Meta的生成式AI负责人Ahmad Al-Dahle在社交平台上发布了一篇长文,回应了对于Llama 4的质疑。Ahmad表示,由于Llama 4刚开发完就迅速发布,所以模型“在不同服务中表现出了参差不齐的质量”,公司会尽快修复漏洞。同时,Ahmad否认了Llama 4在训练集中作弊“刷分”的说法。
两天前,4月5日,Meta推出了旗下最受欢迎的模型系列Llama的最新一代模型,包括较小模型Scout和标准模型Maverick这两个版本。此外,Meta还展示了被称为“迄今最强大、最智能”的模型Llama 4 Behemoth的预览。
据介绍,Llama 4模型是Llama系列模型中首批采用混合专家(MoE)架构的模型,在多模态性能上表现出众。其中,最先进的Llama 4 Behemoth的总参数高达2万亿,担当了其他模型的“老师”;Scout和Maverick的活跃参数量为170亿,Scout主要面向文档摘要与大型代码库推理任务,Maverick则专注于多模态能力。

Meta一次性介绍三款Llama 4模型。来源:Meta
作为原生多模态模型,Llama 4采用了早期融合(Early Fusion)的技术,通过使用大量无标签文本、图片和视频数据一起来预训练模型,将文本和视觉token无缝整合到统一的模型框架中。此外,Llama 4在长文本能力上也取得了突破,Scout模型支持高达1000万token的上下文窗口,Maverick模型则支持100万token的上下文窗口。
不过,Llama 4一经发布就遭到了质疑。Meta的发布界面显示,在评估代码能力的LiveCodeBench测试集和大模型竞技场(Chatbot Arena)中,Scout和Maverick都表现得很不错。但许多开发者发现,这些模型在小型基准测试中的表现令人失望。
例如,有网友指出,在一项让模型完成225项编程任务的名为aider polyglot的基准测试中,Llama 4 Maverick只取得了16%的成绩,远低于Gemini 2.5 Pro、Claude 3.7 Sonnet和DeepSeek -V3等规模相近的旧模型。
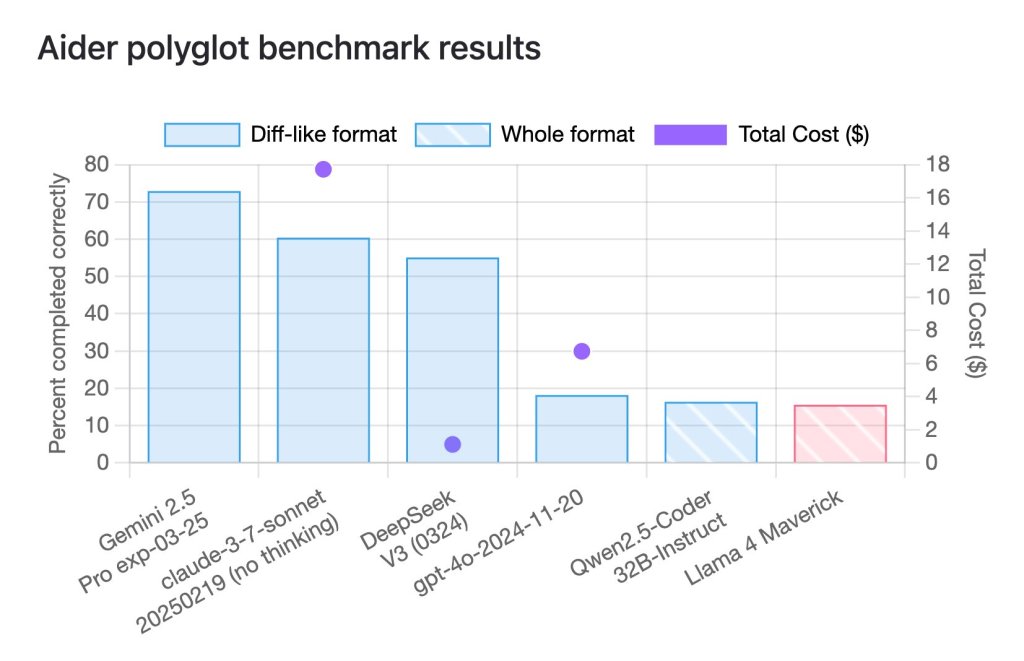
Llama 4 Maverick在小型测试集上成绩不如人意。来源:X平台
AI工程师和技术作家Andriy Burkov则在社交平台X上指出,Meta称Llama 4 Scout拥有1000万token的上下文窗口,而这其实是一个“伪命题”:“实际上,不会有任何模型针对超过256000个token的提示词进行训练。如果你向它发送这么多token,在大多数时候只会得到低质量的输出。”
对于Llama 4令人失望的表现,一些开发者开始怀疑,为了在测试集中取得更好的成绩,Meta为这些测试集制作了“特供版”Llama 4。例如,前Meta研究员、现任AI2(艾伦人工智能研究所)的高级研究员Nathan Lambert在经过比较测试后指出,在大模型竞技场中取得成绩的Llama 4 Maverick与该公司公开发布的版本不同,前者是“在对话性上进行了优化”的版本。
此外,就在Llama 4发布的前几天,在Meta工作了8年的AI研究主管Joelle Pineau宣布离职。联系到Llama 4的表现,更加深了网友对于Llama 4“暗箱操作”的质疑。而在国内社交平台上,也有自称为Meta内部员工的网友称“Llama 4的训练存在严重问题”,自己已经向公司提交了离职申请,AI研究主管的离任也是出于同种原因。
这位网友表示:“经过反复训练,其实内部模型的表现依然未能达到开源SOTA(指在研究任务中表现最好的模型),甚至与之相差甚远。公司领导层建议将各个benchmark(基准)的测试集混合在post-training(后训练)过程中,目的是希望能够在各项指标上交差,拿出一个‘看起来可以’的结果。”
可以肯定的是,Llama 4的初始发布并没有给AI社区带来巨大的积极反响。目前,面对进步迅速的中国AI模型,Meta急于稳住Llama系列在开源领域的领先地位。今年2月,阿里通义千问(Qwen)系列模型的下载量已经达到了1.8亿,累计衍生模型总数达到9万个,衍生模型数超越Meta的Llama系列,成为了全球第一大开源模型系列。
7日当天,Meta(Nasdaq:META)股价涨2.28%,收于每股516.25美元,总市值1.31万亿美元。
上一篇:邮政快递运输工具名称解析
下一篇:继承权,夫妻共同财产的重要体现
相关文章
热门文章

出生时间属于时间类概念
2025-03-31 15:49:33一审未查夫妻共同财产揭示财产纠纷真相
2025-03-31 15:40:49连云港无人机助力平安好助手强化技能训练
2025-03-31 15:29:36对重疾险热议的冷思考
2025-03-31 19:00:04单招铁路专业要求全面解析
2025-03-31 16:37:26神奇化妆秘诀,提升美丽与自信的有效化妆品
2025-03-31 18:42:12
中国政府中东问题特使翟隽会见俄罗斯副外长博格丹诺夫
2025-03-31 17:53:02
欧洲央行官员考虑是否暂停降息之际 欧元区通胀放缓
2025-04-01 17:44:02
有话要说...